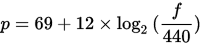React前端表单解决方案对比
背景
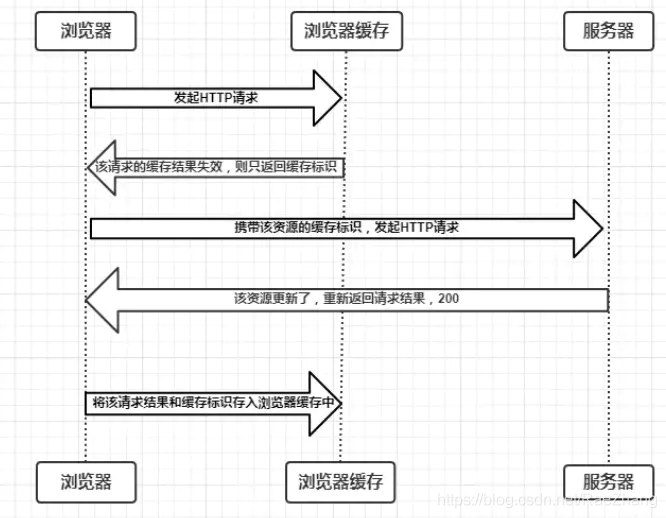
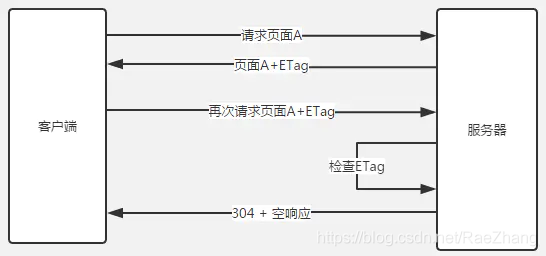
渠道对接需要编写大量重复职位信息的表单,怎样才能减少编写重复表单代码呢?
业务场景核心诉求:
- 具备远程动态渲染能力。也就是支持根据配置动态渲染表单。
- 支持完善的动态逻辑表达能力。 在表单配置层面,能够完善的应对业务场景中出现的联动及动态校验场景。
- 拥有完善的自定义能力。因为需要使用内部 UI 组件实现。
- 有处理异步数据源的能力。比如一个下拉选项,可选项需要从后端异步拉取,这是非常常见的需求。但如何让一个静态的 JSON 表达异步请求,是一个难点。
常见方案分析
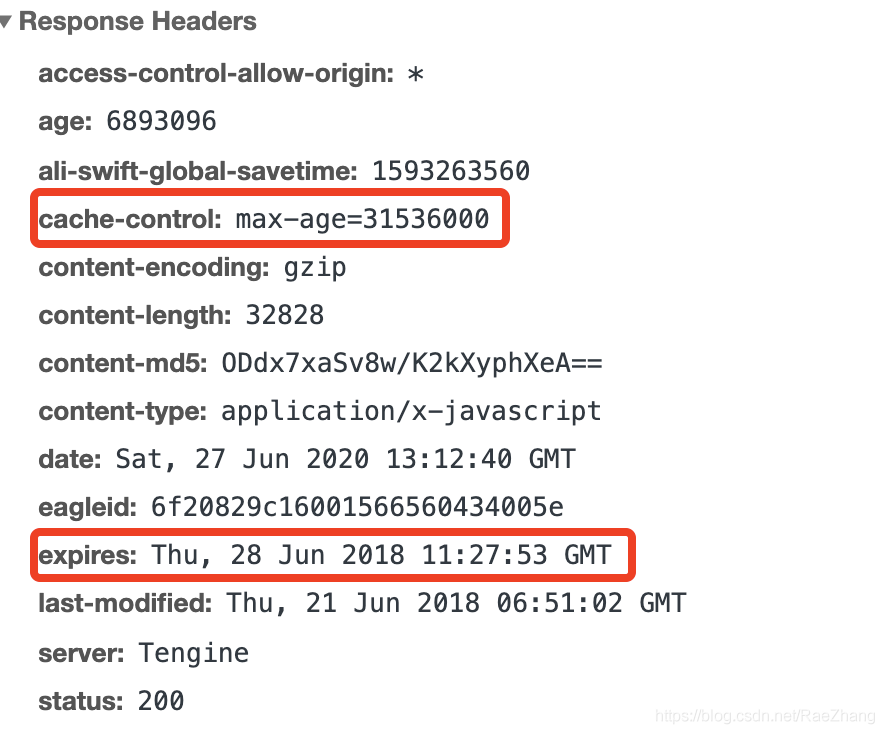
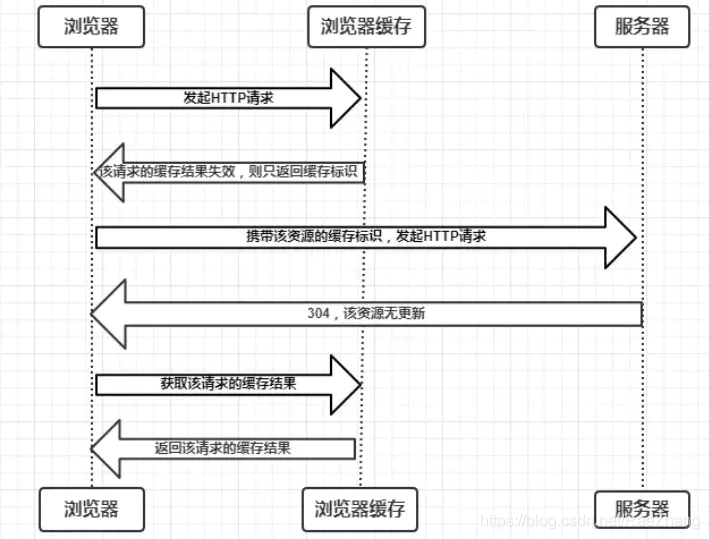
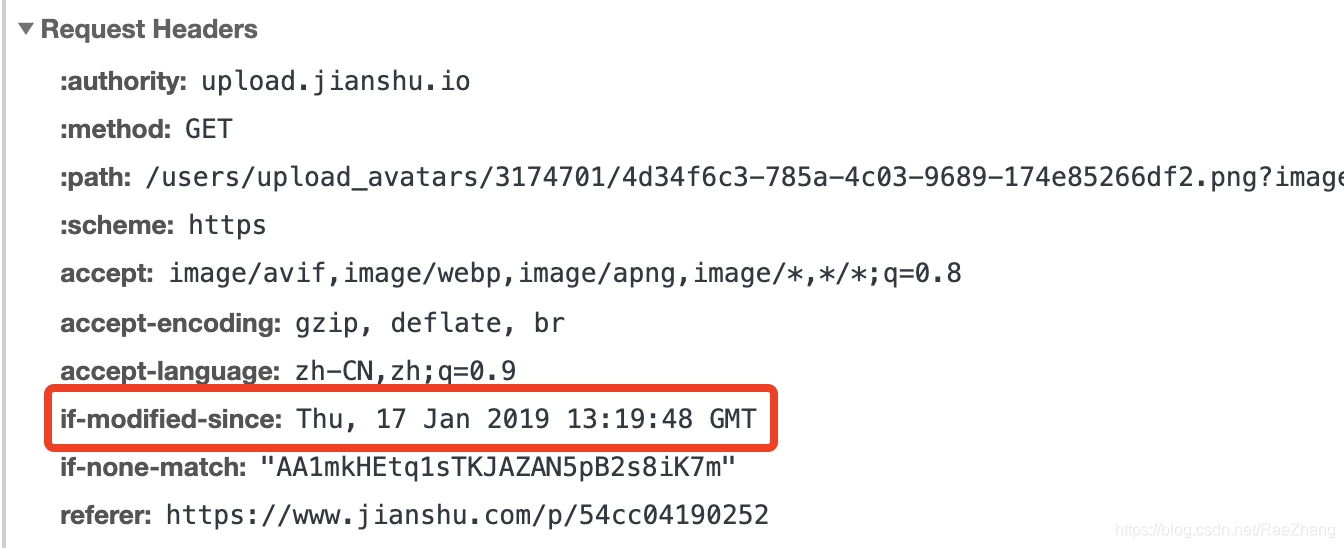
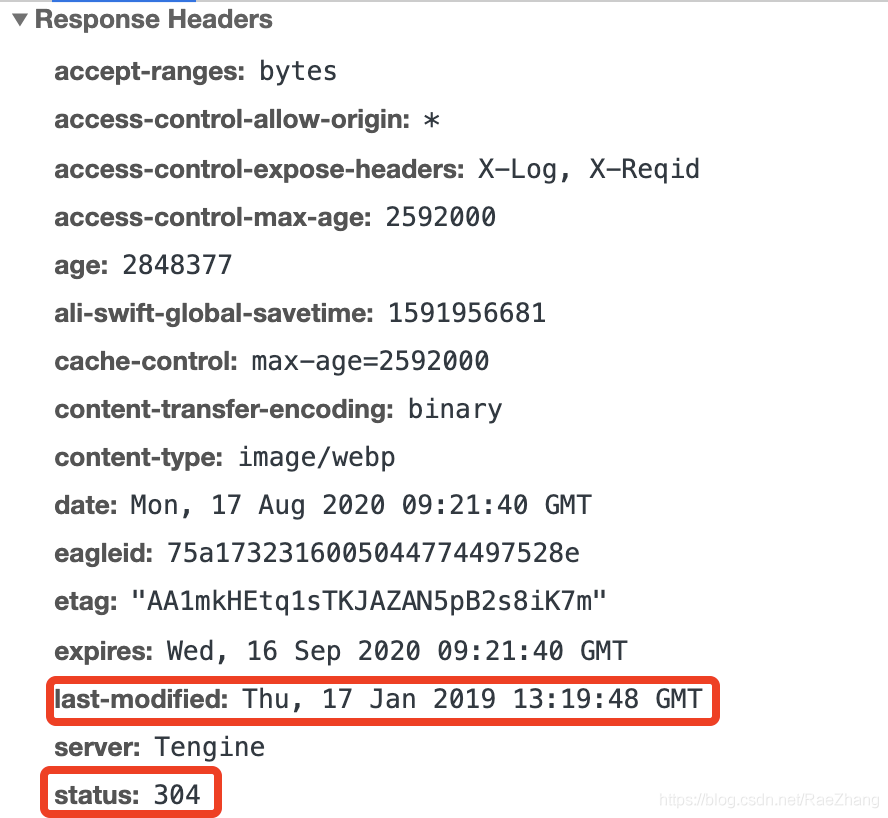
社区支持度数据截止是本文编辑时 (2023.07.05),最新社区数据需要自行前往 github 确认
Formily 是阿里开源的动态化表单的解决方案,优雅的解决了多种复杂场景的表单的数据、状态管理及夸表单通信问题,同时规避了全量全然的弊端,性能优越,生态完备
XRender 是一套基于 React.js 框架的,轻量、易用、易上手的中后台「表单 / 表格 / 图表」解决方案
Formik 是一个流行的 React 表单库,它提供了一个简单但功能强大的 API 来处理表单状态和验证。Formik 支持多种输入控件类型和验证规则,并且可以自定义表单布局和提交行为。
React Hook Form 是另一个流行的 React 表单库,它采用 Hook API 来处理表单状态和验证。React Hook Form 专注于性能和易用性,可以处理大量的表单数据,并提供了一系列方便的工具和组件来构建表单。
Formily
社区支持度
Github Stars: 9.8K
优点
- 功能丰富:提供了非常丰富的功能,包括表单状态管理、表单验证、表单布局、表单联动等。而且 Formily 的功能非常灵活,可以满足各种不同的表单需求。
- 性能优秀:性能非常出色,它采用了一些优化策略来提高表单渲染和处理的效率,例如虚拟滚动、异步渲染、缓存等。
- 扩展性强:提供了非常灵活的扩展接口,开发者可以通过插件、中间件、渲染器等方式来扩展 Formily 的功能。
- 生态完备:生态圈非常完备,包括了大量的插件、工具、组件等,可以满足各种不同的表单需求。
缺点
- 依赖较多,整体体积较大,压缩前 130k,压缩后 80k,包含桥接组件库
- 学习成本较高,文档不够完善
这里附上一个 Formily 官方的 竞品对比
XRender
社区支持度
Github Stars: 6.2K
优点 :
- 高性能:XRender 使用 GPU 加速技术,能够快速渲染复杂的表单界面,提高表单的渲染效率和用户体验。
可扩展性:XRender 提供了可扩展的组件和插件机制,支持自定义组件和表单校验规则,方便用户根据具体需求进行扩展和定制。 - 灵活性:XRender 提供了丰富的表单控件和布局方式,支持多种数据格式和表单交互方式,具有较高的灵活性。提供的playground 工具可以方便用来边写边看表单效果。
- 兼容性:XRender 兼容性良好,能够支持大多数主流浏览器和操作系统,同时也能够支持移动设备。
缺点
- 不支持动态数据拉取
- 依赖较多:XRender 依赖于许多其他的前端框架和库,如 React、Vue、Ant Design 等,使用时需要引入相应的依赖和资源。
Formik(React 官方推荐)
社区支持度
Github Stars: 32.6K
React 官方推荐
优点
- 简单易用:提供了简洁易懂的 API,使得表单处理变得更加容易。
- 具有可扩展性:提供了灵活的插件系统,可以通过插件来扩展其功能,例如使用 Yup 插件进行表单验证。
- 与 React 无缝集成:完全基于 React,可以与 React 的生命周期方法和状态管理库(如 Redux)无缝集成,方便开发者进行开发。
- 高性能:采用了优化的渲染策略,仅在需要时才更新表单的组件,从而提高了性能。
缺点:
- issue 中 bug 较多
- 表单样式需要自己处理:Formik 只提供了表单处理逻辑,不包含任何样式,需要自行添加样式,不过也正好适合自定义 ui 的情况
React Hook Form
社区支持
github stars: 35.7K
优点
- 足够轻量,以及使用 ref 保存值的特点,使它在性能敏感的场景有足够的吸引力。
- 对非受控组件的场景支持很好。
- 为动态变化的表单项提供了 custom-hooks,简洁的 API 帮助开发者应对复杂的场景。
- 强大的类型支持。
- 友善的社区和快速的支持。
- 支持多种表单校验方式。
缺点
和 Formik 类似,不包含任意样式,某种程度上也是优点,支持自定义 UI。
总结
Formik 和 React Hook Form 更多是处理表单的性能和校验问题,并不是原生就支持根据配置动态渲染表单。
Formily 和 XRender 二者都支持 根据 JSON Schema 动态渲染表单。
Formily 功能全面,但体积更大,接自定义 UI 组件成本高,学习成本也高;
XRender 本身附带的有一个开源的表单编辑器。已经集成了物料拖拽等基础交互,所以,整体的表单编辑器可以基于它进行二次开发。渲染器这部分, 可以利用它易用的自定义组件能力整体将内置组件封装一层异步逻辑去支持缺失的异步数据源等功能,扩展性会比较强。这个 x-render 实际应用集合里有一些比较成熟线上例子。
总体来看,如果不是自己造轮子的话,XRender 更适合当前业务场景的需求。
其他
方案调研阶段,只看了 Formily 相关的文档,发现学习成本较高,包体积大,使用自定义组件成本高,同时使用的 JSON Schema 配置很复杂,所以没有采用。
虽然自己造轮子解决了类似的表单场景,但通过调研开源方案发现了自己的轮子缺失的部分,比如我使用了自己定义的表单字段规则而不是标准的 JSON Schema 对象,优点是联动和校验相比标准 JSON Schema 都要简单一些,缺点则是无法借助 ajv 等工具对配置对象进行有效性检测,只能全部依赖于人工测试。后期如果表单功能拓展,需要往 XRender 或者 其他方案迁移会存在阻碍。
如果能重来,我应该会选 标准 JSON Schema 规则约定表单配置, 方便自动检测、后期维护和迁移。表单渲染器部分还是会自己实现,因为需要使用内部的 UI 组件,而且需要异步获取数据,这两项对 XRender 的二次开发成本和自己实现一个简单的表单渲染器实际可能差不多,相比较之下,内部实现的代码更好维护一些。